
The model picked Duke to win it all. Duke lost to UConn in the Elite Eight on a three-pointer with half a second left. The model picked Duke vs. Michigan for the championship. Michigan made it.
So I rebuilt the model, fed it everything that actually happened, and asked it to pick the one game that's left. It picked Michigan. With conviction. Over UConn. The same UConn that has now beaten the model's picks twice.
You see the problem.
The Setup
After the Final Four, I re-ran the bracket predictor in Colab with every actual result locked in through Saturday night. Then I trained a second model, a "late-round specialist," on nothing but Elite Eight, Final Four, and championship games going back to 2008. The theory: late-round games play differently than Round of 64 games. Fewer upsets, tighter margins, different signal. Give the model a focused dataset and see what it says.
Both models said Michigan. Loudly.
Full stacked ensemble: Michigan 66.9%, UConn 33.1%.
Late-round specialist: Michigan 78.1%, UConn 21.9%.
Blended: Michigan 72.5%, UConn 27.5%.
Then I ran 10,000 Monte Carlo simulations with noise injected into the feature deltas to see how robust the pick was. Not a single simulation out of 10,000 had UConn above 50%. The 5th-to-95th percentile band for P(UConn) landed between 24.8% and 29.9%. The model isn't just picking Michigan, it's picking Michigan with both hands and refusing to consider alternatives.
Monte Carlo distribution: P(UConn wins) across 10,000 simulations
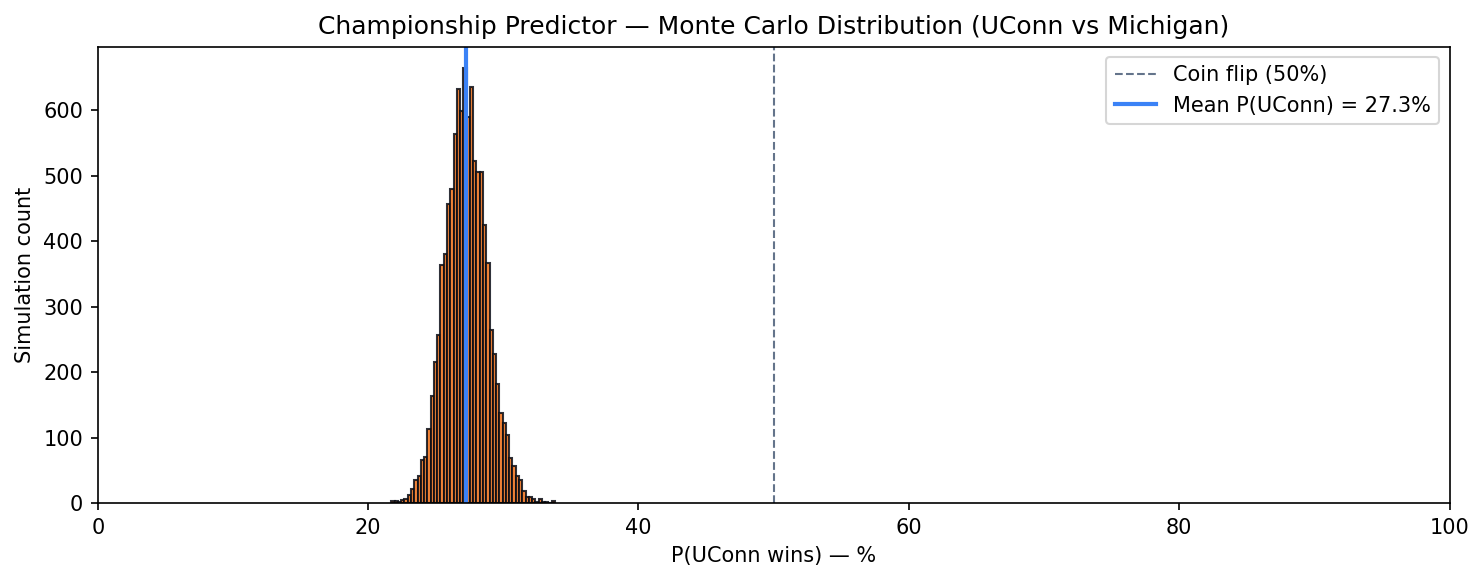
10,000 simulations, every one of them below 50% for UConn. The tallest bars sit right around 27%, which is the blended model's point estimate.
The score projection, using tempo-adjusted offensive and defensive efficiency: Michigan 78, UConn 72. Michigan by 6.6. That margin maps almost exactly to a 72% win probability, which is a nice internal consistency check. The classifier and the score projection are telling the same story from different angles.
The Obvious Problem
This is the same model that picked Duke to win the championship. Duke is at home.
This is also the same model whose accuracy decayed every round:
The Cumulative Scorecard
| Round | Record | Accuracy |
|---|---|---|
| Round of 64 | 22/32 | 68.8% |
| Round of 32 | 11/16 | 68.8% |
| Sweet 16 | 5/8 | 62.5% |
| Elite Eight | 2/4 | 50.0% |
| Total | 40/60 | 66.7% |
The model was a coin flip in the Elite Eight. A coin flip that picked Duke. A coin flip that picked Houston, which got destroyed by Illinois in the Sweet 16.
And here's the part that should bother me more than it does: UConn has now beaten the model's picks twice. First Duke in the Elite Eight, on the Braylon Mullins three. Then Illinois in the Final Four, in a game where Illinois had been the most dominant defensive team in the tournament. The model did not see UConn coming either time. And now the model is telling me, with 72.5% confidence, that UConn will not make it three.
I am not sure the model has learned its lesson.
What the Numbers Actually Say
Strip out the narrative and the numbers are doing something sensible. Michigan has been the most dominant team in the tournament by efficiency margin. They put 95 on Tennessee in the Elite Eight. They put 91 on Arizona in the Final Four. Aday Mara had 26 in that Arizona game. Yaxel Lendeborg has been a wrecking ball. Michigan is shooting the ball at a top-five level and defending at a top-ten level and their tempo favors the kind of game where talent wins.
UConn got here on a buzzer-beater, then on a grind-it-out win over Illinois. Dan Hurley is making his third Final Four in four years, which is absurd. The 2-seed nobody picked is 40 minutes from a title. The model does not care about any of that. The model cares about KenPom adjusted efficiency margin, Barttorvik's BARTHAG rating, quality wins, and about 40 other numbers, and on every one of them Michigan grades out better.
The model is probably right on the inputs and possibly wrong on the conclusion. That's been the story of this whole tournament.
Why I'm Publishing This Anyway
I built the model. The model picks Michigan. I owe you the Michigan pick.
I also owe you the caveat, which is that the model is 40-for-60 with a declining accuracy curve and a track record of getting wrecked by UConn specifically. A 72.5% probability is not a guarantee. It's a Tuesday night starter on your fantasy team. You take it and you watch.
If Michigan wins, the model finishes with a respectable 41-for-61 and I write a post about how late-round efficiency metrics are underrated. If UConn wins, the model finishes 40-for-61, Dan Hurley gets his third title, and I write a different post about how small samples, clutch experience, and a hot freshman on a three-point line are things that 40 features in a CSV cannot capture.
Either way, there's one game left. The model has an opinion. I have Michigan 78, UConn 72. Monday night, 8:30 PM ET, Lucas Oil Stadium, TBS.
After that, there's nothing left to predict. Just a final scorecard and a long offseason to figure out which features the model should have been paying attention to the whole time.
The full code, the updated Colab notebook, and the live tracker are on GitHub.